tesseract
Tesseract OCR
Tesseract is the default Optical Character Recognition (OCR) engine for Robot. It is a free open source component supported on all major platforms.
The integration is based on the Tesseract command line interface (CLI) and the local file system. The desktop image is magnified (scaled up) for better accuracy and saved in the 8-bit black & white format to a file in the system temporary path. The method then starts Tesseract through the CLI with the image file as an argument. The engine performs OCR and stores the recognized text into a text file in the temporary path which is then parsed by Robot.
Set Up Instructions
As the first step find out if Tesseract is available on your system:
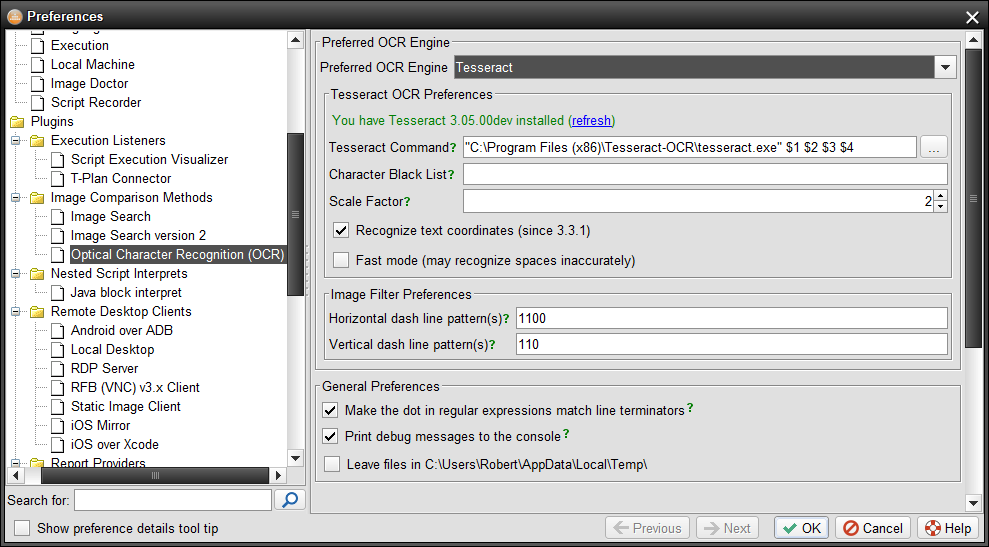
- Start Robot and select the OCR → Choose Preferred OCR Engine in the main menu
- Make sure that Tesseract is selected in the engine drop down.
- If you see a green note like "You have Tesseract XXX installed" then you are all set. Otherwise follow the steps below to install it.
Installing Tesseract
If you are on Linux then simply install the 'tesseract' package using your package manager.
In other cases download and install Tesseract (instructions).
- For Windows it is highly recommended to use the latest UB Mannheim Tesseract installer which also installs the optional language files.
- Tesseract version 5 requires Robot release 6.3 or higher to suppress Form Feed characters in the recognized text.
Robot by default presumes that the tesseract binary is on the system path. If it is not so you update the Tesseract Command field in the above image appropriately. For example, if you installed the engine to the C:\Program Files\Tesseract folder then update the command template to:
"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe" $1 $2 $3 $4
Verify Tesseract
To test out the integration open the Script → Compareto Command window while a script editor is open. Choose "tocr" in the Comparison method drop down and let the window check for Tesseract.
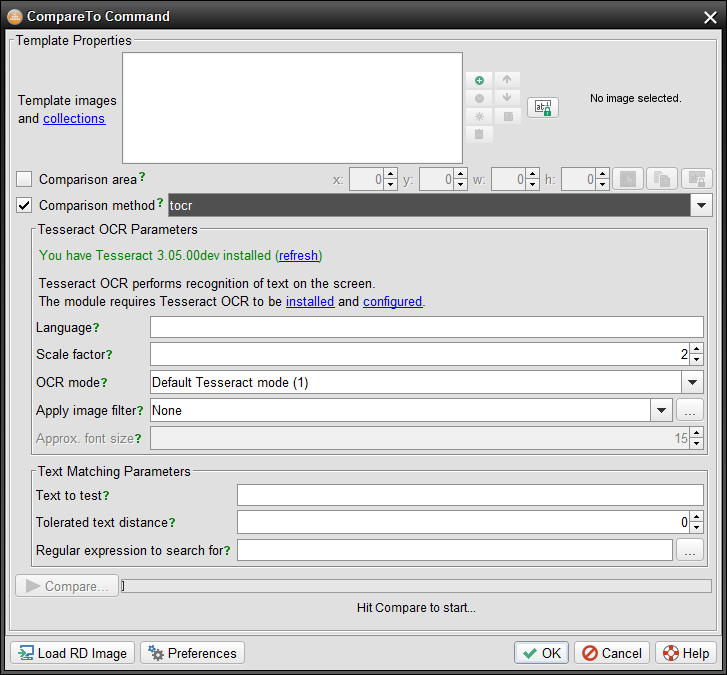
To test whether the Tesseract OCR is correctly installed and configured simply run a "tocr" recognition through the "Compare" button while you have a connection to a test environment. It will either display the OCR results or any error thrown by the engine. The most common errors are:
- Tesseract is not installed at all.
- Tesseract is installed but it is not on the system path. In this case you have to locate the Tesseract OCR preference panel in the Preferences window and update the command template with a full path to the "tesseract" binary.
- Tesseract is installed and configured but it has no language data files or it doesn't have the one specified by the language parameter. In this case you may have to download the language files and store them to the folder required by Tesseract.
As Tesseract's recognition capabilities are limited to most common fonts and languages T-Plan doesn't guarantee any accuracy and/or compatibility with a particular test environment. The Tesseract engine can be eventually "trained" for the particular font or language settings. The steps are described in Tesseract's documentation.
The accuracy can be controlled on the Robot side only through two parameters:
- Limiting the recognition to a particular screen area through the cmparea parameter significantly improves the accuracy. Full desktop recognition seems to distract the engine which often finds text even where there's not any. This leads to unexpected results with many errors.
- As the engine seems to have problems recognizing a standalone string consisting of 1-2 characters use it for longer texts only (3+ characters).
- Higher values of the "scope" parameter such as 2.5 or 3 may slightly improve the accuracy, for example when the font is very small.
Automation
All commands employing OCR such as CompareTo, WaitFor, Click and Drag will use the preferred engine and they will pick up Tesseract automatically.
The OCR makes the calling command return 1 when the OCR throws an error caused by misconfiguration or an I/O error. Text of the error is made available through the _TOCR_ERROR variable. Testing of existence of this variable is a way to detect core OCR errors in scripts.
There are five Tesseract OCR specific parameters:
language=<3-charLanguageCode>
The language parameter be a valid 3-character language code of a properly installed Tesseract language data file. If the parameter is omitted it defaults to "eng" (English).
scale=<scaleFactor>
The scale parameter defines how many times the desktop image will be magnified before it is passed to Tesseract. Scaling may have an impact on accuracy. See the Troubleshooting paragraph for more.
The scale value can be any float number such as 1.5, 2 or 3. High scale values significantly increase memory requirements and may cause Robot to run out of memory (OutOfMemoryError). The default scale factor is 2.
mode=<modeNumber>
Optional recognition mode (supported since 3.5). It allows to modify the engine behaviour to get better results. The supported modes are:
- Default Tesseract mode (code "1"). It is the Tesseract's default mode of automatic page segmentation with no OSD (the "-psm 3" CLI switch). This value is compatible with the Robot releases prior to 3.5.
- High accuracy (code "2"). This is a Robot enhancement which splits the text on the screen into lines and reapplies the OCR to them separately in the line mode (-psm 7). This approach is several times slower but typically delivers more accurate results, especially where the OCR is applied to a smaller screen area such as an application window.
- Treat the image as a single word (code "8"). Use this mode when the recognized text is up to 3 characters long. This is Tesseract's native mode driven through the "-psm 8" CLI switch.
Robot version 4.0.1 and higher supports additional modes:
- Assume a single column of text of variable sizes (code "4") corresponding to the "-psm 4" Tesseract CLI switch.
- Assume a single uniform block of vertically aligned text (code "5") corresponding to the "-psm 5" Tesseract CLI switch.
- Assume a single uniform block of text (code "6") corresponding to the "-psm 6" Tesseract CLI switch.
- Treat the image as a single text line (code "7") corresponding to the "-psm 7" Tesseract CLI switch.
- Treat the image as a single word in a circle (code "9") corresponding to the "-psm 9" Tesseract CLI switch.
- Treat the image as a single character (code "10") corresponding to the "-psm 10" Tesseract CLI switch.
filter=<filterNumber>
Optional image filter (since 3.5). It removes certain artifacts on the screen in order to improve the OCR accuracy. The filter should be applied selectively where the target screen or its part contains text of dark color in rectangular solid color areas, such as for example application windows with standard solid gray or white buttons, drop downs and other components. White or bright color text and rich color graphics such as images or photographs are not suitable for filtering. Usage of the filter in such scenes may damage the text and decrease the OCR accuracy.
fontsize=<fontSize>
Approximate font size of the recognized text (since 3.5). The default value is 15. It is used only when the image filter is on. It tells the filter not to remove artifacts that are smaller than or equal to the font size. When the value is much smaller than the actual font size the filter may cripple some of the characters. When the value is too large the filter will fail to remove certain artifacts (components) from the screen which may result in lower accuracy.