charcapture
Image Based Text Recognition
Contents:
1. Using Image Based Text Recognition in Robot
2. Character Image Collections
3. Character Capture Wizard
1. Overview
Image Based Text Recognition (IBTR) is a new feature introduced in T-Plan Robot Enterprise 3.0 allowing to recognize text and its coordinates on the screen based on a collection of presaved characters. The IBTR functionality consists of three components:
- The "text" comparison method which is described in the Scripting Language Specification.
- Character image collections,
- Character Capture wizard.
This feature is not parameter compatible with the Image Based Text Recognition plugin provided as an add-on for the 2.x releases. To convert the plugin based script code replace the tolerance parameter with the passrate one where
passrate = 100 * (1 - tolerance/85)
An approximate table of the sample tolerance values converted to pass rates:
tolerance | passrate |
|---|---|
0 | 100 |
10 | 88 |
20 | 76 |
30 | 65 |
40 | 53 |
50 | 41 |
60 | 29 |
70 | 18 |
85 | 0 |
2. Character Image Collections
A Character Image Collection is a directory with character images which meets these conventions:
- The collection directory contains just folders named 'uNNNN' (a "character folder") where 'NNNN' is the four digit upper case hexadecimal UTF-8 character code. For example, the 'M' character must be represented by a folder called 'u004D' because its UTF-8 code is 77 (0x4D).
- Each character folder contains one or more character images in a Java supported lossless format (PNG is preferred, BMP is also supported but tends to be large). The image file names are not relevant but the file extensions must be correct with regard to the image format. For example, a PNG image must be stored in a file with the ".png" extension.
An example of a character collection containing two variants of the 'a' character and one 'o' character may look like: C:\MyAutomation\charset
- u0061\
- a1.png
- a2.png
- u006F\
- o.png
- o.png
Collection Recommendations:
- As the internal algorithm derives the height of the text line and the space size from the collection images, do not mix images of characters of different font type and/or size into a single collection. Mixing of character images of different font and background colours is OK as long as the characters are of the same font type and size.
Though Robot supports creation and maintenance of character image collections through the Character Capture Wizard, any such a collection may be created and edited by hand or in third party image editors provided that the conventions are met. This may be useful to exploit some features of the image search algorithm used internally by the IBTR. For example, to create a character collection which would work on any background one may edit the character images in an image editor and make the background transparent or translucent.
3.2 Character Capture Wizard
The Character Capture Wizard is the front end GUI window allowing to create, view and maintain character image collections. The wizard can be started through the Tools->Character Capture menu item.
The very first wizard screen titled Select Image Collection deals with selection of the character image directory to work with:
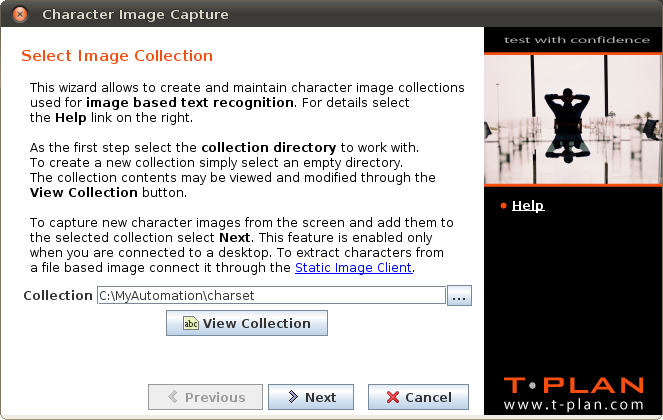
The View Collection button is enabled only if the Collection field contains an existing directory. It opens a new window with the collection details consisting of a tree of character images and a UTF-8 char set table showing which characters are covered by the collection. The viewer also allows basic maintenance tasks such as editing or deletion of the character images.
To add new character images to the selected collection click Next to proceed to the Select Text screen. Note that this button is enabled only when Robot is connected to a desktop. If you need to extract characters from a static image stored to a file, use the Login Window to load the image though the Static Image Client.
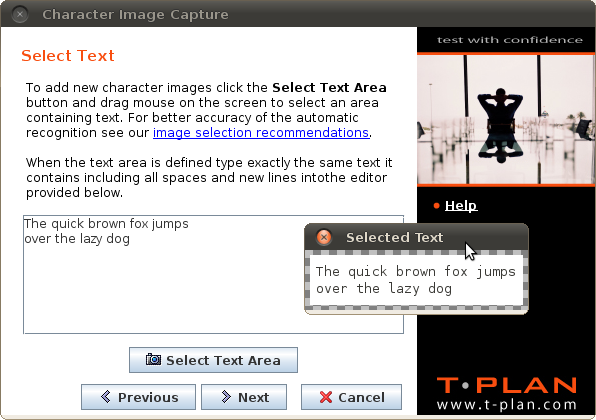
To extract new characters from the screen perform the following steps:
- Click the Select Text Area button. It will open a new window with a copy of the remote desktop. Then drag your mouse in the image to mark the area containing text. See the recommendations chapter below for text selection tips. Once you are satisfied click either the green tick button next to the selection or the Save & Close button on the tool bar.
- Type the text the image contains into the editor situated above the button. Make sure to provide it exactly as it is displayed with all spaces and lines.
Once you have selected the image and provided the text hit Next to proceed to the last screen called Confirm Character Images:
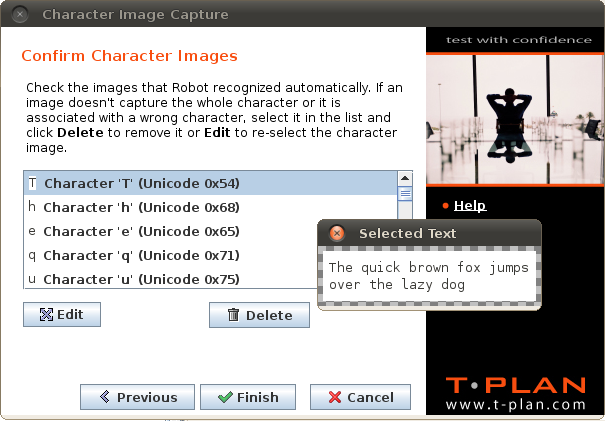
This screen shows the list of characters contained in the provided text. If Robot recognizes the individual characters on the pixel level in the image the list gets populated with the suggested character images. Characters may be removed or modified the the Delete and Edit buttons. Be aware that you don't have to deal with duplicate images. If a character image already exists and it is the same as the newly extracted one, it will be skipped automatically. In some scenarios Robot may fail to parse the text area image for individual characters. This may happen for example when the selected text area does not meet the recommendations criteria. Unrecognised characters then appear in the list with the red N/A icon such as this one:

This behavior does not mean that the character can not be searched using the character collections. It merely indicates that the wizard was not able to suggest the character image. To fix this simply select the character in the list, click Edit and define the its image in the text area manually.
Text Area Selection Recommendations
These tips suggest how to select the text area on the screen in order to minimize the number of unrecognized characters (N/A) which have to be fixed manually:
- The very first pixel of the selected area (the top left corner) must be of the background color.
- The area should contain text of a single font type, size and color displayed on a solid color background such as for example a block of black text on a white background. If the text does not meet these requirements process it in smaller parts which meet this criteria (by words and/or lines).
- The area should contain one continuous block of text displayed on a single graphical component, such as a text message, a button label, a menu item etc.. Do not select for example an area which contains two or more buttons because their texts may be aligned differently along the horizontal axis.
- As Robot separates the characters by looking for a space of background color between them, fonts where characters overlap along the vertical or horizontal axis fail to parse and must be extracted manually. If such a character image contains parts of another character, these must be removed in a third party image editor such as Gimp and the affected must be made transparent to make the character search algorithm skip them.
3.3 The "text" Comparison Method
At the level of test scripts the Image Based Text Recognition is supported in form of a new comparison method called "text" which can be employed through calls of the CompareTo, Screenshot and Waitfor match/mismatch commands or its Java test script counterpart methods. The comparison method supports the following parameters:
- The standard comparison parameters of "cmparea" and "passrate" are supported. The "cmparea" one can be used to limit the text recognition to a particular rectangular area of the screen. The "passrate" one is currently not used. If it is defined by the calling command it is ignored.
- The "chars" parameter is mandatory and defines the path of the character image collection. If the path is relative it is resolved against the script's template directory.
- The "tolerance" parameter is similar to the one supported by the Enterprise Image Search method ("search"). It must be an integer number between 0 and 256. It indicates how much the Red, Green and Blue components of a desktop pixel may differ at a maximum to consider the color be equivalent to the corresponding character image pixel. This value allows to search for characters which are rendered with minor differences in a dynamic way. If the parameter is not specified, it defaults to zero and the algorithm compares pixels using exact color match.
- The "text", "distance" and "pattern" parameters perform the same functionality as their counterparts in the Tesseract OCR method ("tocr").
The method returns the same return values as the Tesseract OCR method. When none of the "text", "distance" and "pattern" parameters is used the calling command returns 0 (success) to indicate a successful execution even when no text gets actually recognized. If the text matching parameters are used the calling command will return either success (0) or fail (non-zero value) depending on whether the recognized text matches or not. The method also populates a set of variables similar to the Tesseract OCR method. These can be used by the calling script to process the recognized text:
Variable Name | Description |
|---|---|
TEXT=<text>_ | The recognized text (full multiline format). The variable is created always when the method gets executed successfully (meaning that it doesn't fail for a missing desktop connection or invalid character image collection). |
TEXT_LINE<n>=<text>_ | Parsed text line where <n> is the line number. Numbering starts from one.If the method recognizes just a single line of text the content of the _TEXTvariable will be equal to _TEXT_LINE1. |
TEXT_LINE_COUNT=<number>_ | Number of lines in the recognized text. |
TEXT_ERR=<error_text>_ | Error message. It gets populated only if the method fails to perform text recognition, for example when there is no desktop connection or when the specified character image collection doesn't exist or can not be read. |
TEXT_MATCH=<text>_ | The part of recognized text that produced a fuzzy match meeting the criteriaspecified in the "text" and "distance" parameters. |
TEXT_MATCH_INDEX=<number>_ | Position (index) of the matching text described in _TEXT_MATCH. Indexingstarts from 0 which corresponds to the beginning of the recognized text. |
The following examples show how to call the text recognition in a .tpr script. More advanced examples on text matching can be found in the Tesseract OCR method documentation whose behavior this method mostly mimicks.
Compareto method="text" chars="C:\MyAutomation\charset"
Screenshot test.jpg method="text" chars="C:\MyAutomation\charset"
Waitfor match method="text" chars="C:\MyAutomation\charset"